Overview
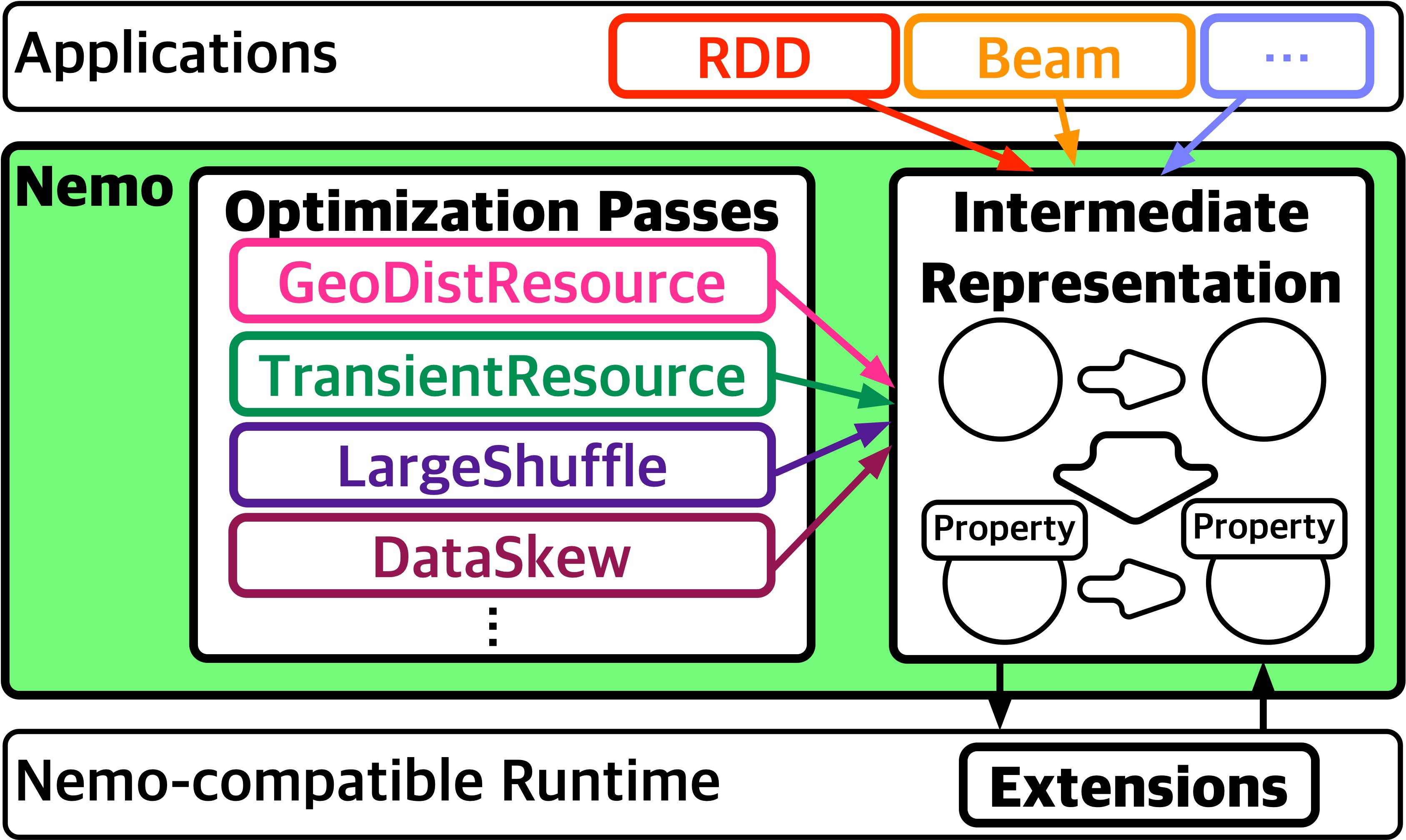
Nemo aims to optimize data processing for better performance and datacenter efficiency, not only in general and common conditions, but also with various deployment characteristics. Such characteristics include processing data on specific resource environments, like transient resources, and running jobs with specific attributes, like skewed data.
There exists many data processing systems with different designs to solve each of such problems it targets, but it fails to cover or adapt to unconsidered cases without substantial effort for modification. The primary reason is because system runtime behaviors are hidden and planted inside the system core to hide the complexity of distributed computing. This makes it very hard for a single system to support different deployment characteristics with different runtime behaviors without substantial effort.
To solve this problem and easily modify runtime behaviors for different deployment characteristics, Nemo expresses workloads using the Nemo Intermediate Representation (IR), which represents the logical notion of data processing applications and its runtime behaviors on separate layers. These layers can be easily modified through a set of high-level graph pass interfaces, exposed by the Nemo Compiler, enabling users to flexibly modify runtime behaviors at both compile-time and runtime. Works represented this way can be executed by the Nemo Execution Runtime through its modular and extensible design.
If you want to contribute, please refer to the contribute page. Otherwise, hit the button below to get started with Nemo!